
「AIアシスタントに昨日の作業を覚えていてほしいのに、毎回リセットされる。」「業務で使っているサービスを横断的にAIに参照させたいが、クラウドにデータを預けるのは不安だ。」
こうした悩みに正面から向き合うオープンソースプロジェクトとして、2026年春に急速に注目を集めているのが OpenHuman です。 OpenHumanは、記憶を持ちながら実際にタスクを実行するAIエージェントです。チャットへの応答そのものはOpenAI・Claude等の外部AIサービスが担い、OpenHumanは記憶の管理・外部サービスとの連携・どのAIに何を頼むかの振り分けを担当します(OpenHuman公式ドキュメント)。ローカルAI(Ollama等)を使えばオフラインでも動作します。
GitHub上のスター数は3万を超え(2026年6月時点)、技術系ニュースレターやエンジニアコミュニティで広く取り上げられています。
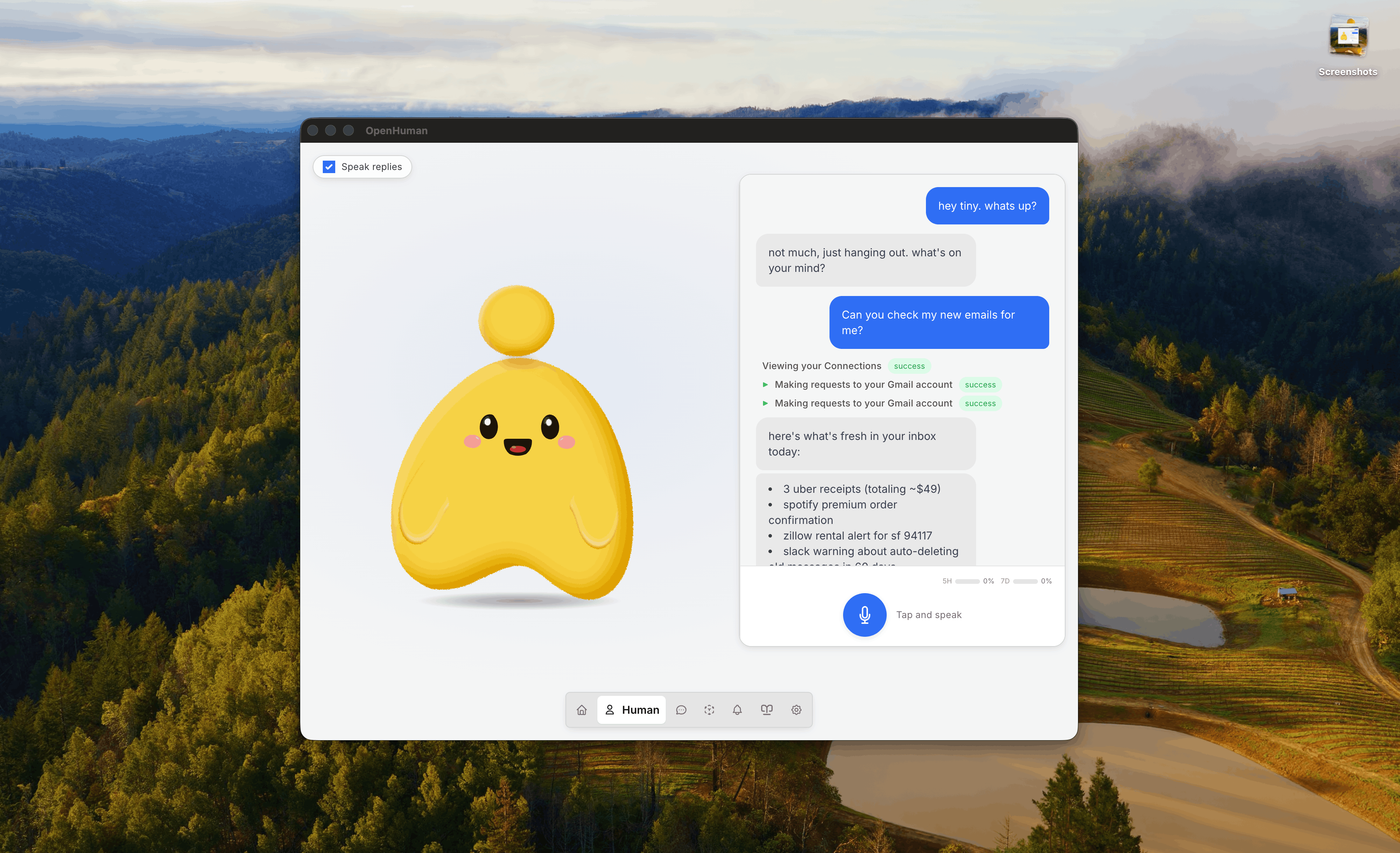 OpenHumanの実際の操作画面。デスクトップ常駐のキャラクターに対し、チャットでメール確認などのタスクを依頼できる(出典: OpenHuman公式GitHub)
OpenHumanの実際の操作画面。デスクトップ常駐のキャラクターに対し、チャットでメール確認などのタスクを依頼できる(出典: OpenHuman公式GitHub)
この記事では、OpenHumanの概要と背景から主要機能・アーキテクチャ・インストール手順・競合との比較・現時点での評価まで、公式情報に基づいて体系的に解説します。
この記事でわかること
- OpenHumanとは何か、どんな課題を解決するプロジェクトなのか
- Memory Tree・118以上の統合サービス・TokenJuiceなど主要機能の仕組み
- インストールに必要な環境とセットアップの大まかな流れ
- Claude Cowork・OpenClaw・Hermes Agentとの違いと、OpenHumanが適しているユースケース
- Early Betaとして把握すべき制限と導入判断のポイント
OpenHumanの概要と背景
どのような問題を解決するプロジェクトか
AIアシスタントの最大の弱点の一つは「忘れること」です。多くのLLMは継続的な記憶機能を備え始めていますが、その記憶はサービスごとに分断されており、長期的な個人コンテキストを一元管理することは難しいです。プロジェクトの背景・人間関係・仕事の流儀——こうした「個人の文脈」を毎回説明し直すコストは、AIをヘビーに使うほど積み重なります。
加えて、クラウド型AIサービスの多くはデータをサーバー側に蓄積します。プライバシーを重視するエンジニアや研究者にとって、業務情報や個人データをクラウドに預けることへの抵抗感は無視できません。
OpenHumanはこの2つの問題に対して「ローカルファーストの永続メモリを持つパーソナルAIエージェント」というアプローチで答えようとしているプロジェクトです。チャット履歴や統合サービスから取得したデータは原則としてローカルのSQLiteデータベースに保存され、エージェントは次のセッションでもその知識を参照して応答します。ただしデフォルト設定では一部の処理がクラウドを経由します(詳細はアーキテクチャの項で解説します)。
開発元・ライセンス・プロジェクト状態
OpenHumanは、開発者集団 tinyhumansai が開発・公開しているオープンソースプロジェクトで、ライセンスは GNU GPL-3.0、ソースコードの閲覧・フォーク・改変が可能です(OpenHuman公式GitHub)。2026年6月5日時点の最新版は v0.57.18 で、公式の位置づけは Early Beta(制限は後述)です。
OpenHumanの主要機能

Memory Tree — ローカルSQLiteに積み上がる永続記憶
Memory Treeは、OpenHumanにおける中核的なメモリ管理の仕組みです(OpenHuman公式ドキュメント「Memory Trees」)。エージェントとの会話内容や統合サービスから取得したデータは、端末内に保存される軽量データベース(SQLite)に記録され、明示的にチャットへ送信しない限り外部に出ない設計になっています。
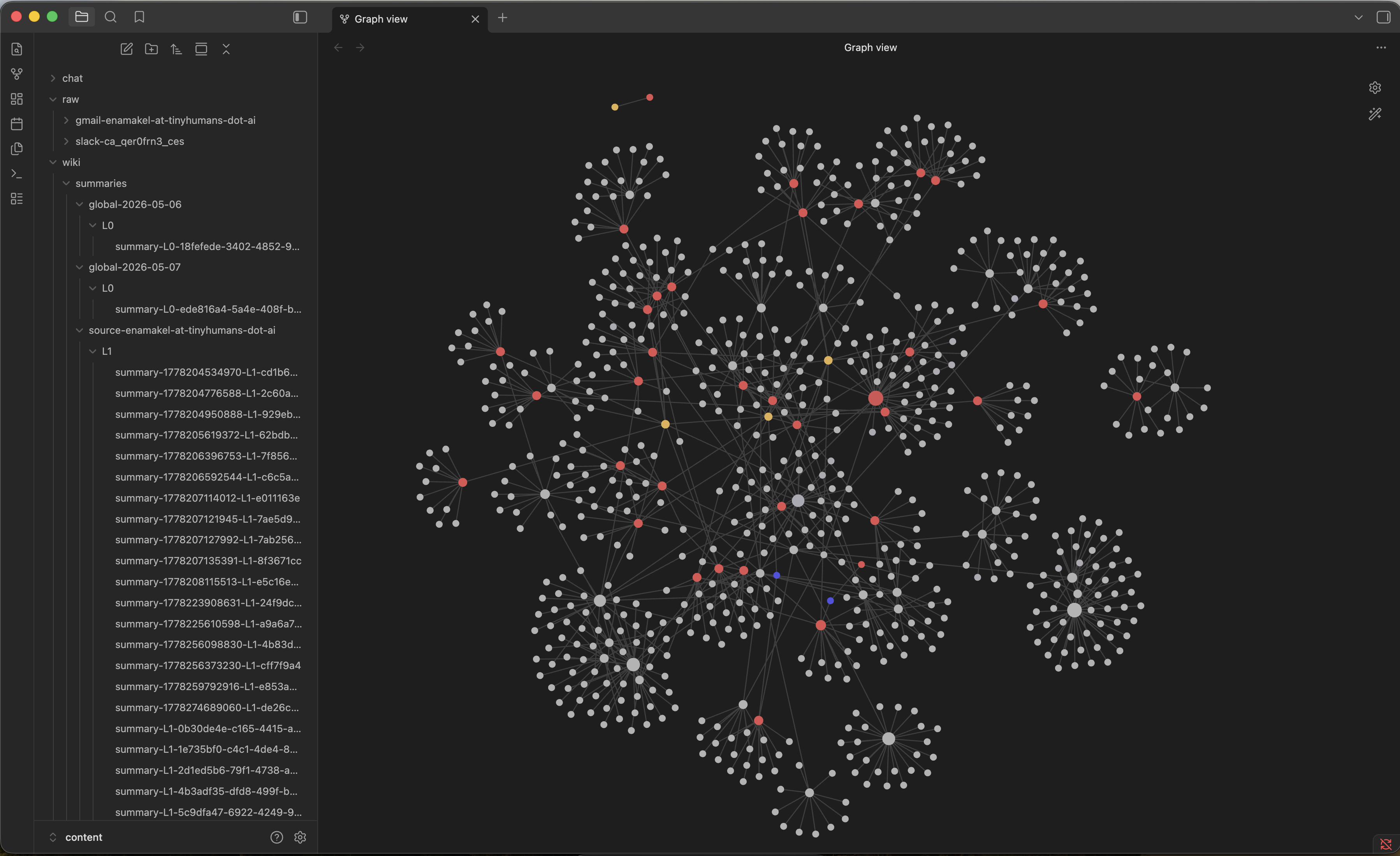 OpenHumanのMemory TreeをObsidianのグラフビューで開いた画面。記憶がMarkdownノートのネットワークとして可視化される(出典: OpenHuman公式ドキュメント)
OpenHumanのMemory TreeをObsidianのグラフビューで開いた画面。記憶がMarkdownノートのネットワークとして可視化される(出典: OpenHuman公式ドキュメント)
ユニークな点は、この記憶が Obsidian互換のMarkdownファイルとしても出力されることです。AIが何を覚えているかを、上の画面のようにノートアプリのグラフビューやMarkdownファイルとして直接確認・編集できます。多くのAIメモリシステムがベクターデータベース内にブラックボックス的に情報を格納するのとは異なり、メモリの透明性が高いのが大きな特徴です。すでにObsidianをナレッジ管理に使っている場合は、OpenHumanのメモリをそのままノートの一部として扱えます。
なお、ObsidianはMarkdownファイルでメモを管理するデスクトップアプリで、ノート同士を[[リンク]]で繋いでネットワーク状に整理でき、データがすべてローカルの.mdファイルとして手元に残る点が特徴です。OpenHumanのメモリはこのObsidianで直接開ける形式で保存されます。
118以上の統合サービス — ワンクリックで外部サービスを連携
OpenHumanは 118以上のサービスとの統合をサポートしています。Gmail・GitHub・Slack・Notionといった代表的な業務ツールと連携でき、エージェントがそれらのデータを横断的に参照・操作できます。各サービスへの接続はOAuth認証でボタン一つで完了し、IDやパスワードを直接渡すことなくアクセス権限だけを安全に委譲できます。
技術的には、統合処理のコネクタレイヤーとして Composio を介しています。このため、サービス連携の認証フロー(OAuth)はデフォルトではOpenHumanのホスト側サービスを経由します。完全なオフライン・セルフホスト環境を構築したい場合は、この点を理解した上で構成を検討する必要があります。
TokenJuice — トークンコスト圧縮の仕組み
OpenHumanが採用するトークン圧縮機能が TokenJuice です(OpenHuman公式ドキュメント「Token Compression」)。大量のパーソナルデータをLLMに渡す際のトークン消費量を抑える仕組みで、公式では6ヶ月分のメール取り込みコストが「数百ドルから一桁ドルになる」という例が示されています。ただしこれは公式が示す例示であり、第三者によるベンチマーク検証は確認されていないため、コストが判断材料になる場合は実環境での計測を前提にするのが安全です。
モデルルーティング — タスクに応じたLLM自動選択
OpenHumanはシングルのLLMに固定されず、タスクの種類に応じて最適なモデルを自動で選択・切り替えるモデルルーティング機能を備えています(OpenHuman公式ドキュメント「Local AI」)。ローカルAI(オフライン推論)にも対応しており、軽量タスクには低コストのモデル、高精度が求められる処理には高性能モデルを使い分ける運用が可能です。
ネイティブツール群 — Web検索・コーダー・音声
組み込みのツール群として Web検索・コードインタープリタ(コーダー)・音声処理が含まれています。標準的なAIエージェントのツール構成をベースに、統合サービスを通じたアクション実行(メール送信・タスク作成等)まで拡張できます。
デスクトップマスコット(オプション機能)
ユニークなオプション機能として、デスクトップに常駐する マスコット(エージェントキャラクター) が用意されています。通知や応答をキャラクター経由で受け取れる「インターフェース層」で、実用機能というよりはUX上の個性として位置付けられており、必須ではありません。
アーキテクチャ詳解
技術スタック(Rust + Tauri v2 + React)
OpenHumanのコアアーキテクチャは以下の技術スタックで構成されています(OpenHuman公式ドキュメント「Architecture」)。
| レイヤー | 使用技術 |
|---|---|
| コアロジック | Rust |
| デスクトップシェル | Tauri v2 |
| フロントエンド | React |
| データ保存 | SQLite(ローカル)+ Obsidian互換Markdownファイル |
| 統合コネクタ | Composio(デフォルト) |
ビジネスロジックをRustコアに集約し、UIとロジックの責任を明確に分離する設計が採用されています。
データフロー10ステップ
OpenHumanのデータ処理は以下の10ステップで構成されます。
- OAuth認証 — 統合サービスへの接続確立
- 自動フェッチ — 接続サービスからのデータ取得
- 正規化 — 取得データの統一フォーマット変換
- チャンク化 — LLMへ渡しやすいサイズに分割
- 保存 — SQLiteへのローカル書き込み
- スコアリング — 重要度・関連度のランキング付与
- 要約 — 長大データの圧縮・サマリー生成
- 検索 — ユーザー入力に対する関連メモリ検索
- 圧縮(TokenJuice) — LLMへ渡すトークン量の削減
- ルーティング — タスクに応じた最適LLMへの送信
このパイプラインにより、外部サービスのデータがローカルで一元管理され、AIエージェントに文脈として提供されます。
ローカル保存 vs クラウド処理の境界線
「ローカルファースト」を正確に理解するために、どの処理がローカルでどこがクラウドを経由するかを整理します。
ローカルで完結する処理:
- Memory Tree(SQLite)へのデータ保存と読み出し
- Obsidian互換Markdownファイルの生成
- ローカルAIモデル使用時の推論処理
デフォルトでクラウドを経由する処理:
- OAuth認証フロー(Composioコネクタを経由)
- クラウドLLM(OpenAI・Claude等)使用時の推論処理
- モデルルーティング処理
重要なのは、デフォルト設定では完全なオフライン・プライベート環境ではないという点です。プライバシーを最優先する場合は、ローカルAIモデルの使用やセルフホスト構成の検討が必要になります。
セキュリティとプライバシーの設計
公式のプライバシー・セキュリティドキュメントでは、データの扱いの要点が次の一文に集約されています(OpenHuman公式ドキュメント「Privacy & Security」)。
生データはチャットメッセージとして送信しない限りマシンの外に出ない(Nothing about your raw data leaves your machine unless you explicitly send a chat message that includes it)
つまり、Memory Tree(SQLite)やObsidian形式のMarkdownファイル、ワークスペース設定は端末上に保存され、クラウドへ送られるのは原則としてユーザーがAIサービスへ明示的に渡したメッセージや処理依頼(Web検索・外部サービス連携・音声処理を含む)に限られます。
認証情報の管理
外部サービス連携に使用するOAuthトークンはOpenHumanのバックエンドが保持し、端末上のディスクにプレーンテキストで書き込まれることはありません。端末ローカルのシークレットはOSのキーチェーン(macOS Keychain・Windows Credential Manager)に保存されます(OpenHuman公式リポジトリ SECURITY.md)。
AIモデルへのデータ学習利用
公式の記載によれば、メッセージコンテンツはリクエスト処理時のみ使用され、AIモデルの訓練や長期保存には利用されないとされています。ただしこれはOpenHuman側の方針であり、接続するAIサービス(OpenAI等)の利用規約とは別であることに注意が必要です。
インストールとセットアップ
必要な環境
ソースからビルドするために必要な環境は以下のとおりです(OpenHuman公式ドキュメント「Getting Set Up」)。
- Node.js: 24以上
- pnpm: パッケージマネージャー
- Rust: 最新の安定版(rustup経由でのインストールを推奨)
- CMake: ネイティブRust依存関係に必要なビルドツール
- Tauri v2 の依存関係: プラットフォームごとに異なる(LinuxではGTKなどのライブラリが必要)
普段Webフロントエンド開発を行うエンジニアには見慣れないツール(Rust・CMake等)が含まれるため、環境構築が初めての場合は余裕をもって作業時間を確保することを推奨します。
インストール手順の概要
公式ではインストーラー配布とソースビルドの2つの経路が提供されています。
インストーラー使用(推奨)
GitHub ReleasesページからOS別のインストーラーをダウンロードして実行します。
ソースからビルド
依存関係のインストール後、リポジトリをクローンします。
git clone https://github.com/tinyhumansai/openhuman.git
cd openhuman
依存パッケージのインストール:
pnpm install
Web UIのみ開発確認:
pnpm dev
デスクトップアプリ開発モードで起動(推奨):
pnpm --filter openhuman-app dev:app
本番ビルドの生成:
pnpm build
まずはインストーラー版で動作を確認し、カスタマイズが必要になった段階でソースビルドに移行するのが現実的なアプローチです。
統合サービスの接続方法
インストール後、アプリ内のIntegration(統合)設定画面から接続したいサービスを選択し、OAuthフローを実行します。接続ボタン一つでOAuth認証が完了し、フェッチが開始されます。118以上のサービスカタログから必要なものだけを選んで有効化できます。
競合比較
同じ「記憶を持つAIエージェント」でも、プロジェクトごとに設計思想は大きく異なります。代表的な3つと並べると、OpenHumanの立ち位置が見えてきます(各プロジェクトの情報は下記公式リポジトリ・公式サイトを確認のうえ整理しています)。
- Claude Cowork(Anthropic / プロプライエタリ・有料プラン専用)— デスクトップ上でファイル・アプリ・ブラウザを直接操作し、タスクを最後まで自律実行する「コンピュータ操作」が強み。モデルはClaudeに固定。
- OpenClaw(MITライセンス / GitHub 37万★超)— CLI中心のセルフホスト型ゲートウェイ。WhatsApp・Telegram・Slack・Discordなど普段使いのチャットツールから呼び出せる「マルチチャネル到達性」が最大の特徴。モデルは自前で用意(BYO)。
- Hermes Agent(Nous Research / オープンソース)— ターミナル前提の自己改善型エージェント。成功したタスク手順をMarkdownの「スキル」として自動的に書き出し、次回以降に再利用する学習ループを持つ。
これら3つと比べたときの、OpenHumanならではの特徴は次の3点です。
| 観点 | OpenHumanの立ち位置 |
|---|---|
| インターフェース | ターミナルではなく、数分で使えるデスクトップGUI |
| メモリ | 記憶をObsidianで開けるMarkdownとして可視化(透明性が高い) |
| 外部連携 | 118以上のサービスとOAuthでワンクリック連携・自動フェッチ |
ざっくり言えば、Claude Coworkの「手軽さ」とOSSエージェントの「自由度」の中間で、記憶の透明性と統合数を前面に出したオープンソースがOpenHumanです。逆に、自律的なPC操作を任せたいならClaude Cowork、チャットアプリからの常時利用ならOpenClaw、自己学習するCLIエージェントが欲しいならHermes Agentに分があります。何を重視するかで選ぶのが現実的です。
OpenHumanが適しているユースケース
- 開発者・研究者として、自分の仕事の文脈をAIに長期的に覚えさせたい
- 複数の業務ツール(Gmail・GitHub・Notionなど)を横断的にAIに参照させたい
- AIのメモリが何を覚えているかを自分で確認・編集したい(Obsidianユーザーに特に相性が良い)
- OSSのエコシステムへの貢献に関心があり、Early Betaでもフィードバックを出していきたい
逆に、商用プロダクションへの即時採用を検討している場合は、現時点では慎重な評価が必要です。
現時点での評価と注意点
Early Betaという段階のため、検討にあたっては以下を念頭に置く必要があります。
- 破壊的変更(後方互換性のないAPIやデータ仕様の変更)が起こりうる
- バグや予期しない動作が安定版ツールより多い可能性がある
- サポートは公式ドキュメントとGitHub Issuesが中心
- 今後の機能・方針が変わる可能性がある
裏を返せば、早期段階のOSSだからこそ、コントリビューターとして参加すること自体がプロジェクトの品質向上に直接貢献できる機会でもあります。Rust / TypeScript / React のいずれかに知見があれば、参入のハードルは高くありません。
まとめ
OpenHumanは、以下の優先度を持つエンジニア・研究者に最も向いています。
- AIのパーソナルメモリを透明性の高い形で管理したい
- ローカルファーストでデータを扱いたい(クラウド依存を最小化したい)
- 複数の業務ツールをAIで横断的に扱う統合エージェントを体験したい
- OSSへの貢献に積極的で、Early Betaのリスクを許容できる
逆に、プロダクション向けの安定性・長期サポートを重視するなら、プロジェクトの成熟を待つか別のアプローチを検討するのが現実的です。AIエージェントが自分の仕事・文脈を覚え続ける未来を、いまオープンソースで手元から試せる数少ない選択肢の一つです。まずはGitHubリポジトリを眺め、インストーラー版から触れてみてください。
出典一覧
OpenHuman公式
- OpenHuman公式GitHub(README・ソースコード) — tinyhumansai(最新 v0.57.18 / 2026-06-05確認)
- OpenHuman公式ドキュメント(Welcome)
- OpenHuman公式ドキュメント「Architecture」
- OpenHuman公式ドキュメント「Local AI」
- OpenHuman公式ドキュメント「Token Compression」
- OpenHuman公式ドキュメント「Memory Trees」
- OpenHuman公式ドキュメント「Getting Set Up」
- OpenHuman公式ドキュメント「Privacy & Security」
- OpenHuman公式リポジトリ SECURITY.md
関連サイト
- Claude Cowork — Anthropicの有料デスクトップAIエージェント(プロプライエタリ)
- OpenClaw — マルチチャネル対応のセルフホストAIアシスタント(MIT)
- Hermes Agent — Nous Researchの自己改善型CLIエージェント(OSS)
- Obsidian — ローカルMarkdownノートアプリ