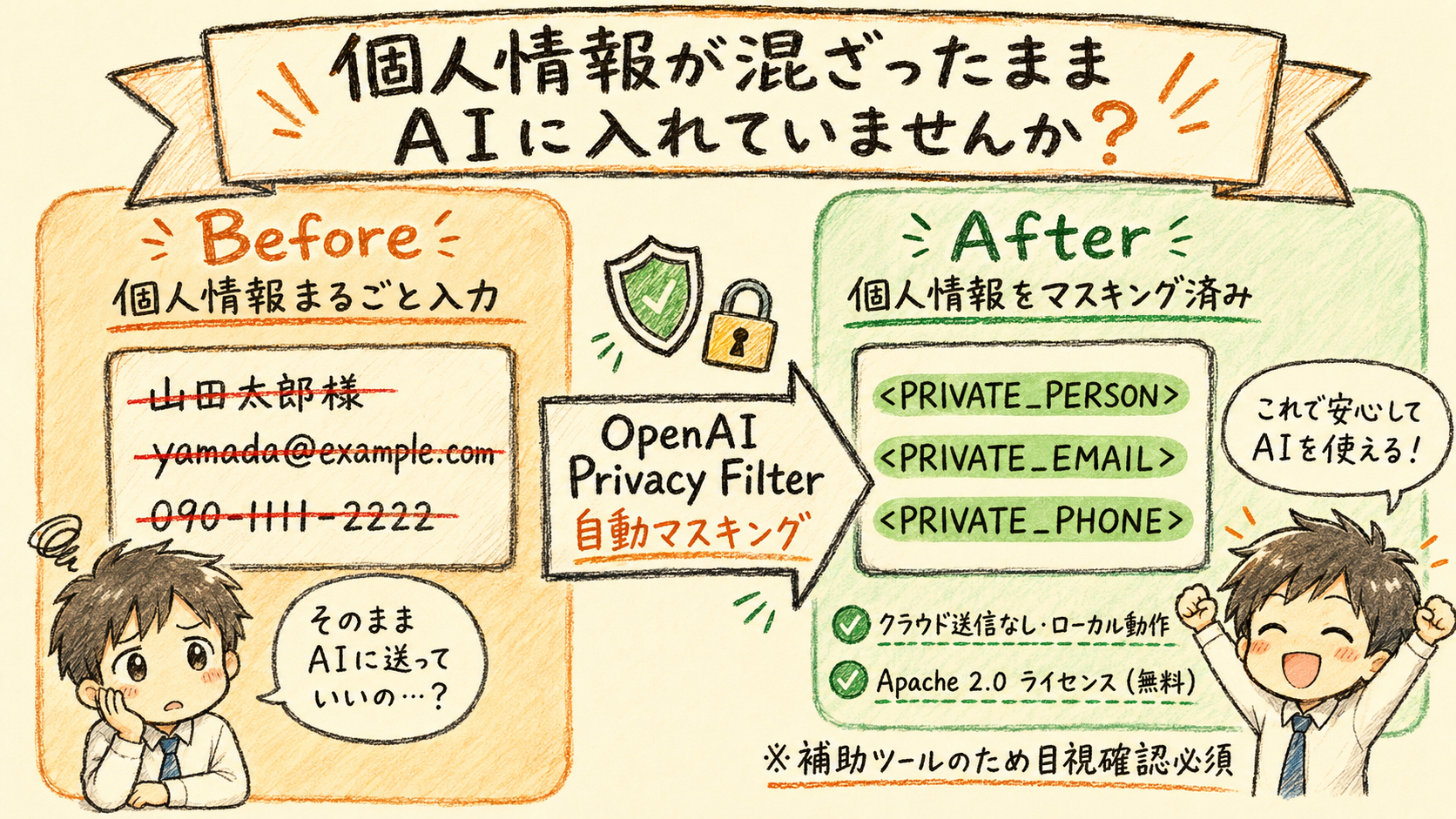
OpenAI Privacy Filterは、テキスト中の個人情報(PII:Personally Identifiable Information)を自動検出してマスキングするオープンソースソフトウェアです。2026年4月22日にApache 2.0ライセンス(商用・社内利用を含めて無料で使えるオープンソースライセンス)で公開され、クラウドに送信せずローカル環境で動作します。 CS・人事・総務などの部門が抱える「AI活用したいけど、入力に個人情報が混ざるのが怖い」という課題に、具体的な解決策を提供します。
「お客様の問い合わせをAIで要約したい。でも、メール本文に氏名や住所が書いてある。クラウドに送信していいの?」
こんな不安を抱えたまま、AI活用を見送っていませんか。その判断は正しいのですが、手段がなければ業務改善も進みません。2026年春、OpenAIはその問題に正面から向き合うツールをリリースしました。
この記事では、OpenAI Privacy Filterの仕組みと限界を正直に解説します。CS・人事・総務など、業務でのAI活用に個人情報リスクを感じているチームの参考になれば幸いです。
- OpenAI Privacy Filterは2026年4月22日公開のオープンソースPIIマスキングモデル。氏名・住所・電話番号など8カテゴリの個人情報を自動検出する。
- ローカル動作(クラウド送信なし)が最大の特徴。社内設置型サーバー(オンプレミス)やPCで動かせるため、社内ポリシーに合わせた運用ができる。
- F1スコア96%の高精度だが、OpenAI自身が「補助ツールであり安全保証ではない」と明言。人間によるレビューが必須。
- CS・人事・総務など個人情報を扱う部門でのAI活用において、個人情報リスクを軽減する選択肢のひとつとして活用できる。
- インストールはGitHubリポジトリをクローン後に
pip install -e .で完了。GPU不要でローカルPCや社内サーバーで動く。
なぜ「入力の個人情報混入」が起きるのか
AIツールへの個人情報混入は、悪意のある行為ではありません。業務の流れの中で、自然に起きてしまうのです。
CS・問い合わせ対応での典型パターン
問い合わせ対応では、返信文の作成を効率化するためにメール本文をそのままAIに貼り付けてしまうことがあります。問い合わせメールには氏名・住所・電話番号などの個人情報が自然に含まれており、意図せず個人情報がAIに送信されてしまうケースが起こりえます。たとえば、メールには以下のような情報が含まれている可能性があります。
- 顧客の氏名
- 連絡先メールアドレス
- 注文番号、購入履歴
- 場合によっては住所や電話番号
これをそのままAIに入力すると、個人情報がOpenAIのサーバーに送信されます。多くの企業の個人情報取扱規程では、第三者サービスへの個人情報提供には本人同意か契約上の根拠が必要です。
人事・総務業務での典型パターン
人事部門でも同様の問題が起きやすい環境があります。採用担当が面接評価シートをAIで整理する場面、総務が議事録をAIに要約させる場面。こうした状況では氏名・生年月日・住所・評価内容など、センシティブな個人情報が混入しやすくなります。
特に注意が必要なのは、以下のケースです。
- 採用書類の整理: 履歴書・職務経歴書をAIに要約させる
- 給与・労務関連: 従業員情報を含む表をAIに処理させる
- 相談窓口の記録: ハラスメント相談や健康相談の内容を入力する
- 契約書処理: 取引先の担当者情報が入った書類を要約させる
「ちょっと要約させるだけ」という軽い気持ちが、個人情報保護法上の問題につながる可能性があります。だからこそ、技術的なガードレールが必要なのです。
OpenAI Privacy Filterとは?できること・できないこと

その技術的なガードレールとして、2026年春にリリースされたのが OpenAI Privacy Filter です。2026年4月22日にOpenAIがApache 2.0ライセンスで公開したオープンソースのPIIマスキングモデルで、テキスト中の個人情報を自動検出し、AIに送信する前にマスキング(伏せ字化)する技術補助ツールです。
8カテゴリのPII自動検出機能
Privacy Filterが対応する個人情報は、以下の8カテゴリです。
| カテゴリ | 検出例 |
|---|---|
| 氏名(Names) | 田中太郎、山田花子 |
| 住所(Addresses) | 東京都渋谷区○○1-2-3 |
| メールアドレス(Emails) | tanaka@example.com |
| 電話番号(Phone numbers) | 03-1234-5678、090-XXXX-XXXX |
| URL | https://example.com/user/profile |
| 日付(Dates) | 1985年3月15日、2026/05/01 |
| 口座番号・クレジットカード(Account numbers) | クレジットカード番号、銀行口座番号 |
| パスワード・APIキー(Secrets) | パスワード文字列、APIキー |
モデルの性能はPII-Masking-300kベンチマーク(個人情報マスキング性能の評価指標)において、F1スコア96%(精度94.04%、再現率98.04%)を記録しています[OpenAI]。感覚的には「100件中96件程度の個人情報を正確に検出できる」精度です。最大128,000トークンまで処理できるため、長い問い合わせメールや会議の文字起こしにも対応できます。
技術的な特徴として、文章を前後両方向から解析する設計を採用しています。 文脈を考慮した高精度なマスキングが可能で、たとえば「山田部長のご連絡先は」という文では、「山田」が氏名として正しく検出されます。
ローカル動作で「クラウド送信なし」の安心感
Privacy Filterの最大の特徴は、デバイス上でローカル動作する点です。テキストをクラウドに送信せずに処理できるため、社内の機密情報を外部サーバーに渡すリスクを大幅に低減できます。
これは企業のセキュリティポリシーにとって大きなメリットです。オンプレミス環境(社内設置型のサーバー)への導入も可能であり、情報システム部門が管理する社内サーバーで運用できます。Apache 2.0ライセンスのオープンソースなので、商用利用も無料です。
なお、初回のモデルウェイトダウンロード時のみ外部サーバー(Hugging Face)へのアクセスが発生します。ダウンロード後の処理はすべてローカルで完結します。オフラインのクローズド環境に導入する場合は、事前にモデルファイルを別途取得する方法を情報システム部門と確認してください。
「補助ツール」であることを忘れない:見落とすリスク
ここが最も重要なポイントです。OpenAI自身が、Privacy Filterについて次のように明言しています。
「このツールは安全保証ではなく、リダクション補助ツール(redaction aid)として使用すべきである」
具体的な限界として、以下の点が挙げられています。
- 珍しい識別子の検出漏れ: 一般的でない氏名や地名は見落とす可能性がある
- 短いテキストでの誤検出: 文脈が少ない場合、過検出・検出漏れが起きやすい
- 曖昧な表現の限界: 「先日お会いした方」など、間接的な個人情報は検出できない
- 医療・法律・金融領域: 専門用語が多い領域では人間によるレビューが必須
つまり、Privacy Filterを使えば「個人情報の混入ゼロが保証される」わけではありません。あくまで人間のレビューを補助するツールです。この前提を理解した上で、社内ルールを設計することが重要です。
実際に導入してみる:インストールから動作確認まで
「使ってみたいが、どう始めればいいかわからない」という声は多いです。ここでは、非エンジニアの担当者でも全体像を把握できるよう、導入の流れをステップ形式で解説します。実際のインストール作業は情報システム部門と協力して進めることを推奨します。
前提条件
Privacy Filterを動かすには、以下の環境が必要です。情報システム部門に依頼する際の参照として活用してください。
| 項目 | 要件 |
|---|---|
| OS | Windows 10以降 / macOS 12以降 / Linux(Ubuntu 20.04以降) |
| Python | 3.10以上 |
| ディスク空き容量 | 約4GB以上(モデルウェイト約2.8GB含む) |
| GPU | 不要(CPU動作対応) |
| インターネット | 初回モデルダウンロード時のみ必要 |
GPU(グラフィックカード)が不要な点は重要です。一般的な業務用PCやオンプレミスサーバーで動作するため、特別なハードウェア投資なしに導入できます。
ステップ1:Pythonのインストール確認
まず、作業PCにPython 3.10以上が入っているか確認します。それぞれ以下のコマンドを実行してください。
Mac(ターミナル):
python3 --version
Windows(コマンドプロンプト):
python --version
Python 3.10.x 以上が表示されれば問題ありません。Pythonが入っていないか、バージョンが古い場合は、python.org から無料でダウンロードできます。
ステップ2:Privacy Filterのインストール
Pythonが確認できたら、GitHubからリポジトリをクローン(ダウンロード)し、インストールします。まず、ファイルを保存したいフォルダに移動してからクローンしてください。リポジトリのクローンとフォルダ移動のコマンドは Mac・Windows共通です。
保存したいフォルダに移動(例:デスクトップの場合)
cd ~/Desktop
リポジトリをクローン
git clone https://github.com/openai/privacy-filter.git
クローンしたフォルダに移動
cd privacy-filter
インストールコマンドはOSによって異なります。
Mac(ターミナル):
pip3 install -e .
Windows(コマンドプロンプト):
pip install -e .
初回実行時にモデルウェイト(約2.8GB)がHugging Faceから自動ダウンロードされます。ダウンロードはインターネット接続が必要ですが、それ以降の処理はすべてローカル(オフライン)で完結します。
社内ネットワークにプロキシ設定がある場合は、情報システム部門にプロキシ設定を確認してから実行してください。
ステップ3:動作確認(テスト実行)
インストール後、動作を確認するためにPythonコードを実行します。実行方法は2つあります。どちらでも結果は同じです。
まず、実行するコードの内容と意味を確認しておきましょう。
from opf import OPF # 「OPFというツールを使います」という宣言
pf = OPF(device="cpu") # ツールを起動(CPUで動かす、GPU不要の指定)
sample = "本件の担当は 山田太郎 です。詳細は yamada@example.com または 090-1111-2222 までお問い合わせください。"
# ↑ ここに処理したいテキストを書く(今回はダミーデータ)
result = pf.redact(sample) # マスキングを実行
print(result.redacted_text) # 結果をターミナルに表示
方法A:ターミナルに1行ずつ直接入力する(対話モード)
ターミナルで python3(Mac)または python(Windows)と打ってEnterを押すと、>>> という記号が表示されます。これがPythonの入力待ち状態です。上のコードを1行ずつコピーして貼り付け、Enterを押して進めてください。
Mac(ターミナル):
python3
Windows(コマンドプロンプト):
python
>>> が表示されたらPythonの入力待ち状態。ここにコードを1行ずつ貼り付けていく
>>> from opf import OPF
>>> pf = OPF(device="cpu")
>>> sample = "本件の担当は 山田太郎 です。詳細は yamada@example.com または 090-1111-2222 までお問い合わせください。"
>>> result = pf.redact(sample)
>>> print(result.redacted_text)
ターミナルに以下のように表示されれば動作確認は成功です。
本件の担当は<PRIVATE_PERSON>です。詳細は<PRIVATE_EMAIL>または <PRIVATE_PHONE>までお問い合わせください。
対話モードを終了するときは exit() と入力してEnterを押してください。
方法B:コードをファイルに保存してまとめて実行する(推奨)
上のコードをテキストエディタに貼り付け、test.py という名前で privacy-filter フォルダ内に保存します。保存時に2点注意が必要です。
① 標準テキスト(プレーンテキスト)で保存する
- Mac(テキストエディット)の場合: デフォルトがリッチテキスト形式のため、メニューの「フォーマット」→「標準テキストにする」を選んでから保存してください。リッチテキストのままだと文字の装飾情報が混入してしまいます。
- Windows(メモ帳)の場合: デフォルトが標準テキストなので、そのまま保存してOKです。
② ファイル形式を .py にする
- Mac: ファイル名を
test.pyと入力して保存します。.txtになっていないか確認してください。 - Windows: 保存ダイアログの「ファイルの種類」を「すべてのファイル」に変更し、ファイル名を
test.pyと入力して保存してください。test.py.txtになっていないか確認してください。
 コードを貼り付けて標準テキスト形式で
コードを貼り付けて標準テキスト形式で test.py として保存した状態。ファイル名が .txt になっていないか確認する
ファイルが保存できたら、ターミナルで privacy-filter フォルダに移動してからコマンドを実行します。
privacy-filter フォルダに移動(まだ移動していない場合)
cd privacy-filter
Mac(ターミナル):
python3 test.py
Windows(コマンドプロンプト):
python test.py
1行ずつ打つ手間がなく、コードの打ち間違いも起きにくいため、こちらの方法をおすすめします。
氏名・メールアドレス・電話番号がそれぞれ <PRIVATE_PERSON>・<PRIVATE_EMAIL>・<PRIVATE_PHONE> に置き換わっていれば、正常に動作しています。
本件の担当は<PRIVATE_PERSON>です。詳細は<PRIVATE_EMAIL>または <PRIVATE_PHONE>までお問い合わせください。
⚠️ 注意: 動作テストには必ずダミーデータを使用してください。実際の顧客情報や従業員情報でのテストは避けてください。
ステップ4:業務フローへの組み込み
動作確認ができたら、実際の業務フローに組み込みます。エンジニアがいる場合は、以下のような自動化の仕組みをSlack上のツールやWebツールとして実装するのが理想的です。
顧客メール受信
↓
Privacy Filter(自動マスキング)
↓
担当者が目視確認(30秒)
↓
マスキング済みテキストをAIに入力
↓
AI出力を業務に活用
エンジニアリングリソースがない場合は、担当者がローカルスクリプトを手動実行する形でも運用できます。まずはシンプルな形でスタートし、効果を確認してから自動化を検討するのが現実的です。
非エンジニア担当者へのポイント
「コードを書いたことがない」という方に向けて、現実的な選択肢を整理します。
- 情報システム部門に依頼する: インストールと基本的なスクリプト作成を依頼し、担当者はUIツールとして使う形が現実的
- SaaSの代替も検討する: Privacy Filterのオープンソース実装ではなく、PIIマスキング機能を持つSaaSツール(Microsoft PurviewのAI機能など)の方が導入ハードルが低い場合もある
- 小さく試す: まず1名の担当者が自分のPCで試験導入し、効果を確認してから全社展開を検討する
完全な自動化を最初から目指す必要はありません。「手動でも動く最小構成」から始めて、徐々に整備することが、現場定着への近道です。
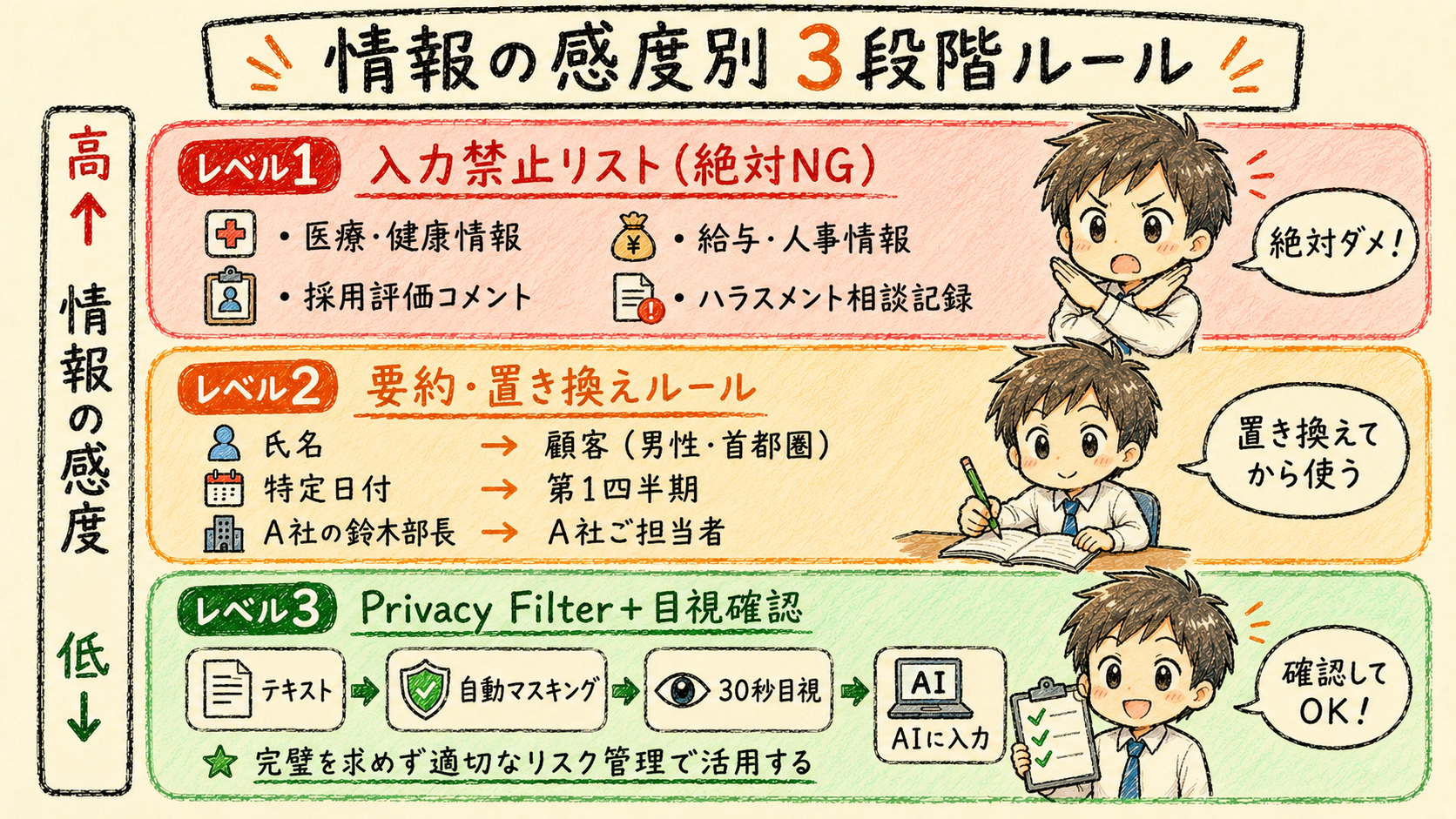
社内の運用ルール例:入力禁止・要約・匿名化の3段階
Privacy Filterを導入しても、社内ルールがなければ現場は混乱します。効果的なのは、情報の感度に応じた3段階のルール設計です。なお、生成AI全般のガードレール設計(情報漏えい対策・ガバナンス・法規制への対応)については、生成AIガードレール完全ガイドで体系的に解説しています。
レベル1:入力禁止リスト(高リスク情報)
どれだけ便利なツールがあっても、AIに入力すべきでない情報は存在します。以下の情報は、一切AIに入力しないルールを徹底してください。
入力禁止の情報(絶対NG):
- 医療・健康情報(診断名、病歴、薬の処方内容)
- 採用選考の評価コメント(本人同意なし)
- 従業員の給与・人事評価情報
- ハラスメント・メンタルヘルス相談の記録
- 取引先との秘密保持義務がある情報
- 本人同意なしに取得した個人情報
これらはPrivacy Filterで検出できるかどうかに関わらず、AIへの入力自体を禁止します。技術的な対策より、ルール自体が最初の防壁です。
レベル2:要約・置き換えルール(中リスク情報)
直接の個人情報は含まないが、組み合わせによって個人が特定できる可能性がある情報は、入力前に「要約・置き換え」を行います。
置き換えの具体例:
| 元の入力 | 置き換え後 |
|---|---|
| 山田太郎様(東京都、30代男性)のご注文について | 顧客(男性、首都圏、30代)のご注文について |
| 2026年3月15日に電話でのご相談 | 2026年第1四半期の電話相談 |
| ○○株式会社の鈴木部長より | A社のご担当者より |
この置き換え作業をすべて手動で行うのは現実的ではありません。そこでPrivacy Filterが活きてきます。ツールを使って自動マスキングを行い、マスク後の内容を担当者が目視確認してからAIに入力するフローを組みます。
レベル3:Privacy Filter+目視確認(低リスク情報)
社内の会議資料や業務マニュアル、一般的な問い合わせ内容など、個人情報混入リスクが低い情報は、Privacy Filterによる自動マスキング後に目視確認を経てAIに入力します。
このレベルのフロー:
- テキストをPrivacy Filterに通す(自動マスキング)
- マスキング結果を担当者が30秒目視確認
- 問題なければAIに入力
- AI出力内容にも個人情報がないか確認
完璧を求めず、「適切なリスク管理をした上で活用する」という判断が、現場定着の鍵です。
最小構成で始める:テンプレ+レビュー体制
「ゼロから体制を設計する余裕はない」という担当者のために、最小構成での始め方を紹介します。
入力前チェックテンプレート(コピーして使える)
以下のチェックリストを、AI入力前に必ず確認するルールにします。Slack・Notionなどに貼り付けて使ってください。
【AI入力前チェックリスト】
□ 氏名(顧客・従業員・取引先)が含まれていないか
□ メールアドレス・電話番号・住所が含まれていないか
□ 生年月日・年齢など個人を特定できる情報がないか
□ 口座番号・クレジットカード情報がないか
□ 医療・健康・採用評価など高感度情報が含まれていないか
□ Privacy Filter(またはレビュー)を通過済みか
□ 出力結果の二次利用範囲は明確か
→ すべてOKなら入力可。1つでも不明な場合は上長に確認。
このチェックリストは、業務フローの「入口」に組み込むことが重要です。AIを使う前に必ず確認するという習慣が、個人情報混入事故を防ぎます。
運用フローの最小構成(3ステップ)
現場で回る最小構成は、次の3ステップです。
ステップ1:担当者によるセルフチェック 上記チェックリストを使い、入力内容を自分で確認します。判断に迷う場合は入力しない、が大原則です。
ステップ2:Privacy Filter通過(ツール活用) レベル2〜3の情報は、Privacy Filterに通してから入力します。ツールの出力(マスキング済みテキスト)を確認し、問題がなければ次のステップへ。
ステップ3:2名以上によるレビュー(高リスク業務) 医療・法律・人事など、高リスク情報を扱う業務では、1名の判断に委ねず、必ず複数人でレビューします。「一人で判断しない」という文化が、インシデントを防ぐ最も有効な仕組みの一つです。
よくある質問(FAQ)
Q: Privacy FilterはChatGPTと直接連携できますか?
A: 現時点ではChatGPT(チャット画面)との直接連携機能はありません。Privacy Filterで処理したテキスト(マスキング済み)を、別途ChatGPTに貼り付けて利用する形になります。API連携での自動化の仕組み構築は技術的に可能ですが、エンジニアリングの工数が必要です。
Q: 日本語の個人情報は正確に検出できますか?
A: 基本的な姓名・住所・電話番号は検出できますが、F1スコア96%は主に英語データによるベンチマーク結果です。日本語は姓名の形式が多様なため、英語と同等の精度は期待しにくく、実環境でのテストが必要です。日本語環境での本格利用には、実際の業務データでの精度テストと、後述する「2名以上のレビュー体制」との組み合わせを推奨します。
Q: 無料で使えますか?
A: はい。Privacy FilterはApache 2.0ライセンスのオープンソースソフトウェアです。GitHubから無料で入手できます。ただし、社内サーバーへ導入する場合はサーバー費用と情報システム部門の作業工数が発生します。個人PCでの試験利用であれば追加費用はありません。
Q: Privacy Filterを使えば個人情報保護法への対応は完了しますか?
A: いいえ。Privacy Filterはあくまで技術的な補助ツールであり、法的なコンプライアンス対応を保証するものではありません。個人情報保護法への対応には、プライバシーポリシーの整備・社内規程の策定・従業員教育を並行して進めてください。
Q: 医療や法律分野の業務でも使えますか?
A: OpenAI自身が、医療・法律・金融などの高感度領域では「人間によるレビューと領域特化のファインチューニングが必要」と明言しています。これらの分野での利用は、Privacy Filterのみに頼らず、必ず専門家のレビュー体制を整えた上で、慎重に進めてください。
まとめ:「安全に使い始める」が最初の一歩
OpenAI Privacy Filterは、個人情報を扱う部門のAI活用を後押しする実用的なツールです。2026年4月22日にApache 2.0ライセンスで公開され、ローカル環境で動作するため、クラウドへのデータ送信なしにPII検出・マスキングができます。
ただし、F1スコア96%の高精度でも、珍しい氏名や間接的な表現は検出を漏らすことがあります。技術ツールと運用ルールを組み合わせた複数の対策を重ねることが、安全活用の前提です。
参考情報: